Process Engine Architecture
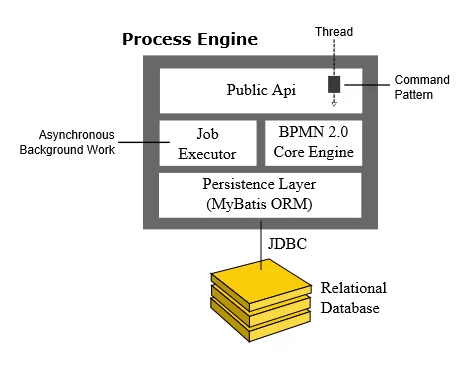
- Process Engine Public API: Service-oriented API allowing Java applications to interact with the process engine. The different responsibilities of the process engine (i.e., Process Repository, Runtime Process Interaction, Task Management, …) are separated into individual services. The public API features a command-style access pattern: Threads entering the process engine are routed through a Command Interceptor which is used for setting up Thread Context such as Transactions.
- BPMN 2.0 Core Engine: This is the core of the process engine. It features a lightweight execution engine for graph structures (PVM - Process Virtual Machine), a BPMN 2.0 parser which transforms BPMN 2.0 XML files into Java Objects and a set of BPMN Behavior implementations (providing the implementation for BPMN 2.0 constructs such as Gateways or Service Tasks).
- Job Executor: The Job Executor is responsible for processing asynchronous background work such as Timers or asynchronous continuations in a process.
- The Persistence Layer: The process engine features a persistence layer responsible for persisting process instance state to a relational database. We use the MyBatis mapping engine for object relational mapping.
Required Third-Party Libraries
See the section on third-party libraries.ASEE Flow Architecture
ASEE Flow is a flexible framework which can be deployed in different scenarios. This section provides an overview of the most common deployment scenarios.Embedded Process Engine
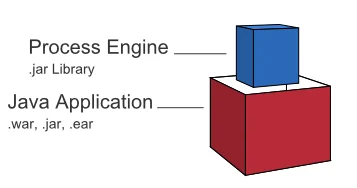
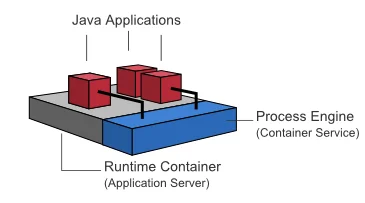
Shared, Container-Managed Process Engine
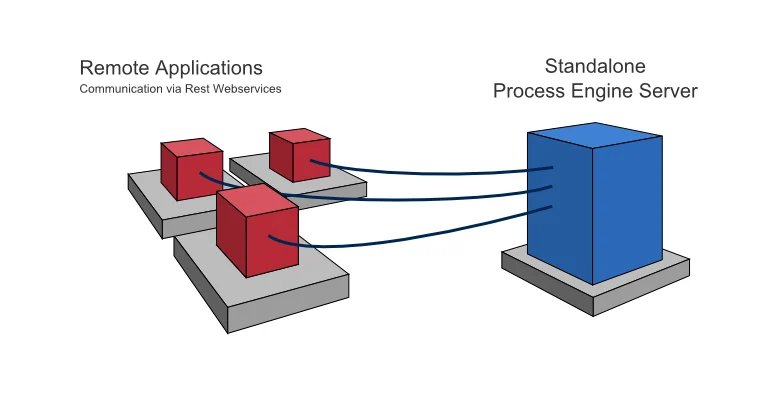
Standalone (Remote) Process Engine Server
Clustering Model
In order to provide scale-up or fail-over capabilities, the process engine can be distributed to different nodes in a cluster. Each process engine instance must then connect to a shared database.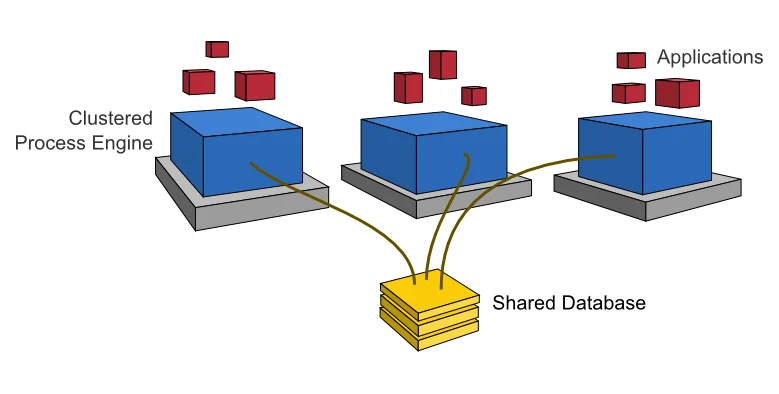
Session State in a Clustered Environment
ASEE Flow doesn’t provide load-balancing capabilities or session replication capabilities out of the box. The load-balancing function would need to be provided by a third-party system, and session replication would need to be provided by the host application server. In a clustered setup, if users are going to login to the web applications, an extra step will need to be taken to ensure that users aren’t asked to login multiple times. Two options exist:- “Sticky sessions” could be configured and enabled within your load balancing solution. This would ensure that all requests from a given user are directed to the same instance over a configurable period of time.
- Session sharing can be enabled in your application server such that the application server instances share session state. This would allow users to connect to multiple instances in the cluster without being asked to login multiple times.
Consistent hashingIf a cookie based consistent hashing is used, make sure that the cookie name is not JSESSIONID which is used by ASEE Flow.
The Job Executor in a Clustered Environment
The process engine job executor is also clustered and runs on each node. This way, there is no single point of failure as far as the process engine is concerned. The job executor can run in both homogeneous and heterogeneous clusters.Time zonesThe are some limitations on time zone usage in a cluster.
Multi-Tenancy Models
To serve multiple, independent parties with one ASEE Flow installation, the process engine supports multi-tenancy. The following multi tenancy models are supported:- Table-level data separation by using different database schemas or databases
- Row-level data separation by using a tenant marker
Web Application Architecture
The ASEE Flow web applications are based on a RESTful architecture. Frameworks used:- camunda-bpmn.js: Camunda BPMN 2.0 JavaScript libraries
- JAX-RS based Rest API
- AngularJS
- RequireJS
- jQuery
- Twitter Bootstrap